
The project explore the Prosper loan loan data set. The data set contains 113,937 loans with 81 variables on each loan, including loan amount, borrower rate (or interest rate), current loan status, borrower income, and many others.
The project explore the Prosper loan loan data set. The data set contains 113,937 loans with 81 variables on each loan, including loan amount, borrower rate (or interest rate), current loan status, borrower income, and many others.

The goal of the analysis is to get atleast 3 insights and 1 visualization from the dataset. We had used the merged dataset which comprised of the enhanced twitter archived data, the image prediction data and the tweet json datasets. A copy of the merged dataset was made and and stored as Twitter_df which was used for the analysis. The Twitter_df dataset contains 1953 rows and 12 columns. Some of the columns includes, ratings, favourite counts, retweet counts, dogs breed, the image url for each dogs, the tweet id, etc.
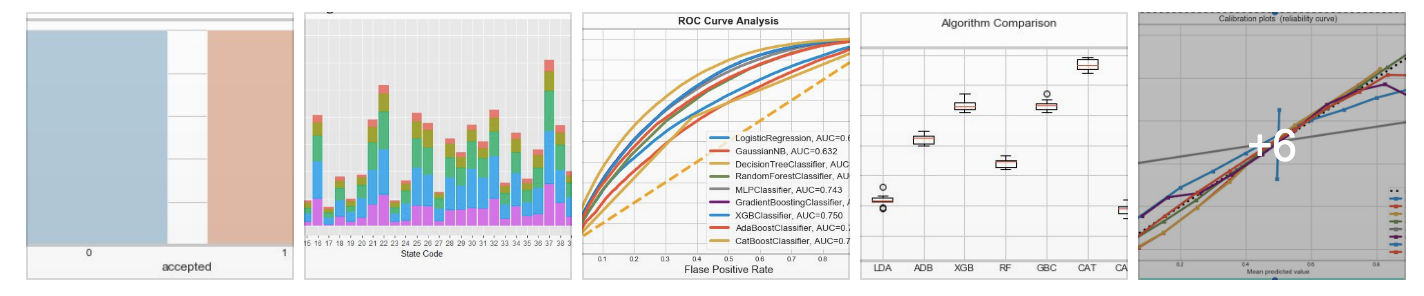
Machine learning and data-driven techniques have become very famous and significant in several areas in recent times. In this paper, we discuss the performances of some machine learning methods on both loan approval.
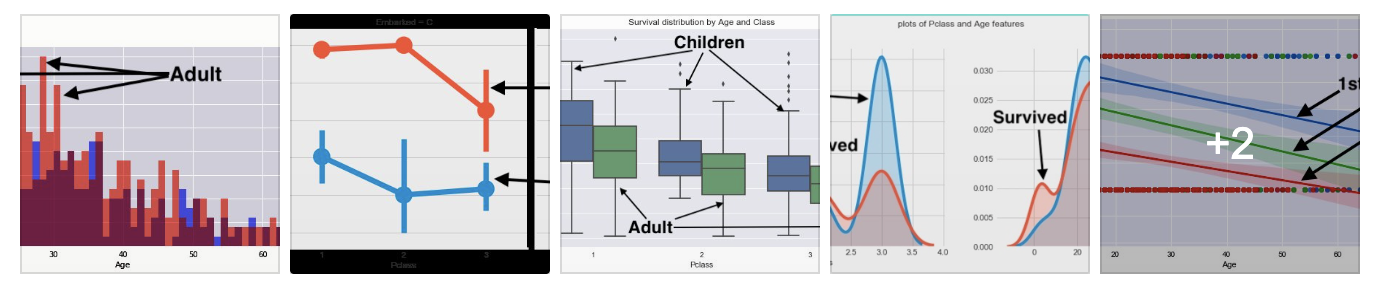
Analysis of Titanic shipwreck is essential in order to understand the historical data. The correlation between the independent and dependent features was observed in order to determine features that may have impact on passenger survival. In this paper, we explored the Titanic data and four machine learning algorithms.

Data analyst, Machine learning, Energy optimization, Applied Mathematics
Hi, My name is Rabiat Ibrahim. 👀 I’m interested in Data science and Machine learning and the applications to solving real world problems. 🌱 I’m currently taking data science and machine learning courses to re-inenforce my knowledge and experience in this field. I’m looking to collaborate on projects in data science.
| Position | Company | Period |
|---|---|---|
| Software support | ☉ Schooltry, Nigeria | June-Sept., 2022 |
| Teacher | Confluence Science Secondary School, Nigeria | Jan. - July, 2017 |
| Teaching assistant | Federal University of Technology, Nigeria. | Oct 2015 - Oct 2016 |






